Python 字符串
本章我们要讲解什么是字符串、Python索引、Python切片、索引和切片对比、字符串类型、字符串常用方法、字符串拼接-join方法、5种字符串的大小写转换方法、5种字符串的检索方法、3种字符串的分割方法、3种字符串的修剪方法、字符串的格式化、%格式化、str.format格式化、f-string格式化、f-string的自定义格式等内容,充分了解Python字符串相关内容。
什么是字符串
在前面我们已经大量使用了字符串,那么究竟什么是字符串呢?就是我们生活中所见的文字、数字、字母、汉字的组合,我们把这种组合就叫做一串,也就是我们Python中的字符串。在生活中字符串的例子随处可见,比如说门户网站,各种标题,内容以及栏位,这些都是字符串。

然后我们再来看一些字符和数字的情况,在注册邮箱的时候让我们填写字符、数字以及下划线,他们也是字符串,所以说在Python中最常见的就是字符串。
创建字符串
那么我们要如何创建字符串呢?创建的方式非常简单有三种方式,单引号,双引号和三个单引号或者是三个双引号
-
单引号创建字符串
# 单引号创建字符串
name = 'andy'
- 双引号创建字符串
# 双引号创建字符串
hoby = "basketball"
- 三个单引号或三个双引号
# 三个单引号或三个双引号
zen ='''
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
'''
- 单双引号混合使用创建字符串
此外需要注意的一点是,字符串中含有一种形式,就是既有单引号又有双引号,比如说这样的一个字符串
print("andy's hobby is basketball")
print('大熊说:"人生苦短,我用python"')
输出结果:
andy's hobby is basketball
大熊说:"人生苦短,我用python"
在字符串中包含单引号和双引号的情况,这时有的小伙伴就会问了,那么我该什么时候使用单引号,什么时候使用双引号的?或者说官方推荐我们使用单引号还是双引号呢?这里郑重的对大家说,你喜欢哪个就用哪个。但是有一个原则:就是你在这个文件里,如果你使用单引号,那么你就全用单引号,如果你使用双引号,你就先用双引号。你不能像这样,又是单引号又是双引号。这样读你代码的人看起来就会很困惑。只要你保持了一致性,别人阅读你代码的时候就不会有那么多困惑,这就是一种良好的编程风格 。
Python转义符
如果我们输出的字符串是用两个单引号包裹了一个单引号,如下面的代码,那我们应该怎么办?
print('andy's hobby is basketball')
不运行输出我就知道我们错了,因为下划线已经为我们提示了错误信息

果然输出语法错误,这是为什么呢?因为在Python中,我们的字符都是匹配的,单引号和双引号他们都是成对出现的,这里的单引号和双引号,而在我们这个字符串中,你中间的这个要输出的内容,它是一个单引号,它自动就会和前面的单引号匹配,这样就导致了后面的单引号没有匹配的内容,所以这里就给我们报错了。
在Python中,转义字符用于在字符串中插入特殊字符或者特殊的语句,例如制表符或者换行符等。在Python中,转义字符都以反斜杠(\)开头,后面跟着一个字符或者一串字符。下面是Python中常用的转义字符:
| 转义字符 | 描述 |
|---|---|
| \\ | 反斜杠 |
| \' | 单引号 |
| \" | 双引号 |
| \n | 换行符 |
| \r | 回车符 |
| \t | 制表符 |
| \b | 退格符 |
| \f | 换页符 |
其中,字符串前缀可以是单引号(')或者双引号("),用于表示字符串的开头和结尾。转义字符和字符串都需要放在引号之间。
实例
实例1:常见转义字符示例
print("Hello\nWorld") # 输出 "Hello" 和 "World" 带有换行符
print('andy\'s hobby is basketball') # andy's hobby is basketball' 带有单引号
print("I said, \"I love Python\"") # 输出 "He said, "I love Python"" 带有双引号
print("Python\tis\tawesome") # 输出 "Python", "is", "awesome" 带有制表符
输出结果:
Hello
World
andy's hobby is basketball
I said, "I love Python"
Python is awesome
虽然转义字符能解决我们的问题,但是通常我们不加这个转义字符,首先他阅读起来就不方便,此外,如果你这个转义字符要是在最后面 那么它很容易出错,所以一般时候我们不加这个转义字符。
作业:
作业一:输出一个带有反斜杠的字符串 "C:\Users"
作业二:输出一个带有单引号和双引号的字符串 "daxiong said, 'Python' is "awesome""
获得作业答案请联系本笔记的配套视频:Python零基础入门动画课【全集】
Python索引
本节我们来学习一下字符串中的索引,那么什么是索引呢?索引它也叫下标,你可以把它理解为能够快速引导我们查找目标的序号。
- 生活中的索引
我们来举几个生活中常见的索引,在阅读一本书的时候,如果这本书很厚,而我们只对某些内容特别感兴趣。那么这个时候你就可以通过目录来查找到你感兴趣的章节,这里的目录它就是一个索引。

在看电影的时候我们可以通过座位号快速查找到你的位置,这里的座位号就是索引,而在吃饭的时候,服务员通过餐桌的桌号来找到你,这个桌号也是一个索引。

我们在存东西的时候,通过存储柜上的编号,你也可以快速找到自己的东西。这个编号它也是一个索引。

- Python中的索引
那么字符串跟索引有什么关系呢?假如说这里有个hello world,你不要把它当做一个整体,你把它切开,如下图。

切开以后你会发现,这个字符串就是由一个个的字符连接起来的,这些字符它是有顺序的。h是第1个字符,它的��下标是0。d是最后1个字符。它的下标是10,我们把它的下标序号就叫做索引。
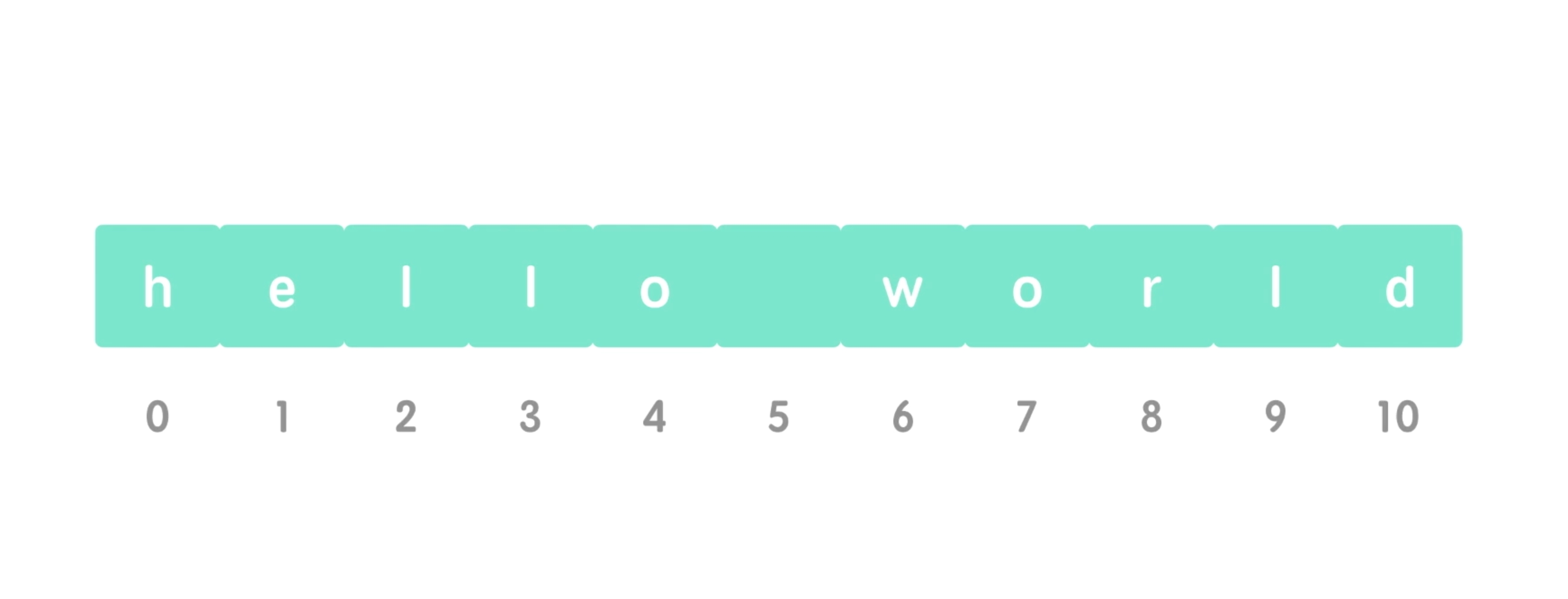
- 为什么下标从0开始?
注意这里的第1个编号是0,也就是说它的索引是从0开始的。这时可能小伙伴会问了,为什么要从零开始呢?我们正常数数,不都是从1开始吗?在很多编程语言中,比如说c语言、Python、Java和PHP,它们的下标都是从零开始的,这是有一定历史渊源的。很多编程语言在设计之初都参考了c语言。而c语言在设计的时候有参考了bcpl语言,bcpl它在使用索引的时候,从0开始记位,这是因为从0开始比从1开始可以加快我们的编译速度,索引索引从0开始,就一直流传了下来 。

- 常见的索引操作
我们已经知道了什么是索引,那么应该如何使用这个索引呢?我举个例子,在易经中有这样一段话,叫做积善之家必有余庆。这句话它是一个字符串。我们定一个变量叫做motto来接收它。这个字符串它的索引是这样的从0~9。我们就可以通过索引来取到这个变量中的每一个字符。

实例
实例1:获取motto的每一个字符
motto = '积善之家,必有余庆。'
print(motto[0]) # 输出motto第1个字符
print(motto[1]) # 输出motto第2个字符
print(motto[2]) # 输出motto第3个字符
print(motto[3]) # 输出motto第4个字符
print(motto[4]) # 输出motto第5个字符
print(motto[5]) # 输出motto第6个字符
print(motto[6]) # 输出motto第7个字符
print(motto[7]) # 输出motto第8个字符
print(motto[8]) # 输出motto第9个字符
print(motto[9]) # 输出motto第10个字符
输出结果:
积
善
之
家
,
必
有
余
庆
。
这就是索引的一个用途,通过索引来找到字符串中你需要的字符。
Python切片
本节我们来学习一下字符串中的切片,本文将详细介绍Python中切片的语法、各个参数的含义。那什么是切片呢?生活中的切片面包大家都熟悉,把一个面包切成一片一片的,下图就是一个切片面包。

第1片面包在索引中它是0,然后是1,2,以此类推,如果我想取第3片面包,我可以通过索引值2来获取到。那么如果我想取多片呢?比如说我从第3片取到第10片,当然你可以通过下标2 3 4 5 6 7 8 9这样来获取。但是显然这太慢了。
在Python中就为我们提供了一个切片的功能。它可以对序列(例如列表、字符串等)进行筛选、截取、复制等操作。
语法
sequence[start: end: step]
其中,sequence表示需要进行切片的��序列(例如列表、字符串等);值得注意的是,start、end、step这三个参数都是可选的,如果不指定start和end,则默认为整个序列;如果不指定step,则默认为1。
start
start表示切片开始的下标(包含),即从哪个位置开始切片。如果不指定start,则默认为0,即从序列的第一个元素开始切片。
end
end表示结束的下标(不包含),即切片到哪个位置结束。如果不指定end,则默认为序列的长度,即切片到序列的末尾。
step
step表示步长,默认为1。步长是切片中一个非常重要的概念,它决定了切片的间隔。比如,当step=2时,表示每隔一个元素取一个元素;当step=3时,表示每隔两个元素取一个元素,以此类推。
实例
实例1:正着数切片截取字符串的值
我们接着以积善之家必有余庆这个字符串为例,假如说我要获取必有余庆这几个字符。我可以通过正着数的方式来获取,它的下标是09
那么必有余庆这几个字符,它的下标是从58。那么我就可以使用切片,像这样

motto = '积善之家,必有余庆。'
print(motto[5:9])
输出结果:
必有余庆
实例2:倒着数切片截取字符串的值
我们知道,索引还可以从后往前,比如说像这样,最后一个句号它的索引是-1,庆是-2,而我们的第1个字符积它的索引就是-10,现在我要获取必有余庆。

motto = '积善之家,必有余庆。'
print(motto[-5:-1]) # 因为它是不包含右值的,所以我们需要再加1位变成-1,这里也需要注意的是不包含右值 。
输出结果:
必有余庆
实例3:省略着数切片截取字符串的值
省略着数,同样的下标是不变的,假如说我要获取从必开始,一直到最后,那么我可以这样,motto[5:],冒号后面不添加任何值,就表示它一直到最后。 同理你可以使用倒着数的方式,倒着数是从-5个开始,那么它就是这样的:motto[-5:]

motto = '积善之家,必有余庆。'
print(motto[5:])
print(motto[-5:])
输出结果:
必有余庆。
必有余庆。
实例4:跳着数切片截取字符串的值
我们再来看另一种方式跳着数,这里的正着数下标是09,倒着数是-1-10,那么跳着数呢,从0~10表示全部的字符串,最后的2它表示每隔一个获取一个 。

motto = '积善之家,必有余庆。'
print(motto[0:10:2])
输出结果:
积之,有庆
实例5:列表切片
# 列表切片
a = [1, 2, 3, 4, 5]
print(a[1:3])
输出结果:
[2, 3]
这个例子中,a是一个包含5个元素的列表,我们使用a[1:3]来获取列表的第2个和第3个元素,即[2, 3]。
作业
作业一:使用切片获取下面列表中的前3个元素。
lists = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
作业二:使用切片获取下面列表中的后3个元素。
lists = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
作业三:请使用切片获取下面列表中的第2个到第5个元素。
lists= [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
作业四:请使用切片获取下面列表中的第2个到第9个元素,并且中间隔一个元素。
lists = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
作业五:请使用切片将下面列表中的第2个到第9个元素反转。
lists = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
获得作业答案请联系本笔记的配套视频:Python零基础入门动画课【全集】
索引和切片对比
在Python中,我们经常需要对字符串或者列表进行操作,其中最基本的操作就是索引和切片。索引是指通过下标获取列表或者字符串中的某个元素,而切片是指通过下标获取列表或者字符串中的一段连续的元素。索引和切片有哪些需要注意的地方?
- 切片区间从小到大
- 切片区间左开右闭
- 索引越界会报错
- 切片越界会自动处理
字符串是不可变类型
在介绍Python的数据类型的时候,我们总会提到一个词,就是可变类型与不可变类型。Python字符串是一种不可变的数据类型,也就是说,它们的值在创建后就不能被更改。这意味着,如果您想要更改一个字符串,需要创建一个新的字符串来代替原始字符串。 什么是可变类型和不可变类型的?可变类型的英文单词是mutable,不可变类型是immutable。

你可以简单的理解为这个类型数据中的元素是否可以发生变化。如果能更改,它就是可变类型,不能更改它就是不可变类型。
实例
实例1:验证字符串是否是可变类型
字符串它是由单个字符串联起来的,我们可以通过索引来找到这个字符。那么我们能不能更改这个字符串中的字符呢?下面我们来验证一下
word = 'python'
word[0]='j'
print(word)
输出结果:
word[0]='j'
TypeError: 'str' object does not support item assignment
这里也提示我们错误信息了:类型错误,字符串不支持赋值操作。那如果我需要一个不同的字符串,应该怎么做呢?我们可以这样,把它们拼接起来。
word = 'python'
word = 'j'+word[1:]
print(word)
输出结果:
jython
这里是生成了一个新的字符串,而不是原来的word,因为字符串它是不可变的。所以要修改的时候,我们只能生成一个新的,而不能对原字�符串中的字符进行操作。
字符串拼接:join方法
在字符串中还支持使用另一个函数,叫做join函数,它用于将一个可迭代对象中的元素连接成一个字符串,并返回该字符串。
语法
string.join(iterable)
其中,string是用于连接可迭代对象的字符串,iterable是需要连接的可迭代对象。
注意,该函数只能将字符串序列连接成一个字符串,如果可迭代对象中有数字、列表等非字符串类型,则需要先将它们转换为字符串类型才能连接。
参数
join()函数的参数包括字符串连接符、可迭代对象、字符串类型的可迭代对象和元组类型的可迭代对象。
实例
实例1:拼接大熊课堂网址
join()函数的第一个参数是字符串连接符,用于在可迭代对象元素之间插入一个固定的字符串,比如下面的例子中,字符串连接符是“.”:
list_val = ['www', 'daxiongketang', 'com']
str_val = '.'.join(list_val)
print(str_val)
输出结果:
www.daxiongketang.com
实例2:拼接日期
我们也可以使用其他字符作为字符串连接符,比如下面的例子中,字符串连接符是“-”:
list_val = ['2023', '06', '01']
str_val = '.'.join(list_val)
print(str_val)
输出结果:
2023-06-01
实例3:字符串类型的可迭代对象
如果可迭代对象中的元素是字符串类型,可以直接使用join()函数连接。比如下面的例子中,可迭代对象中的元素都是字符串类型:
str_val = 'hello'
newStr = '-'.join(str_val)
print(newStr)
输出结果:
h-e-l-l-o
实例4:元组类型的可迭代对象
如果可迭代对象中的元素是元组类型,然后再使用join()函数连接。比如拼接一个路径
mytuple = ('user', 'andy', 'code')
str_val ='/'.join( mytuple)
print(str_val)
输出结果:
user/andy/code
作业
作业一:连接两个字符串'hello'和' world',使它们中间没有空格。结果如下
'helloworld'
作业二:将一个列表[1,2,3,4,5]连接成一个字符串,并用逗号隔开。结果如下
'1,2,3,4,5'
作业三:连接两个字符串'hello'和'world',并在它们之间插入一个连字符-。结果如下
'hello-world'
作业四:将一个元组mytuple = ('www', 'daxiongketang', 'com')连接成一个字符串,并用点号隔开。结果如下
'www.daxiongketang.com'
作业五:将一个列表[1,2,3,4,5]连接成一个字符串,并用-隔开。结果如下:
'1-2-3-4-5'
获得作业答案请联系本笔记的配套视频:Python零基础入门动画课【全集】
5种大小写转换方法
本节我们来学习字符串大小写转换方法,大小写转换有哪些方法呢?主要有这么5种方法如下。
| 方法 | 描述 | 示例 |
|---|---|---|
| str.upper() | 将字符串中所有字符转换为大写字母 | "hello world".upper() |
| str.lower() | 将字符串中所有字符转换为小写字母 | "HELLO WORLD".lower() |
| str.capitalize() | 将字符串的第一个字符转换为大写字母,其他字符转换为小写字母 | "hello world".capitalize() |
| str.title() | 将字符串中每个单词的第一个字符转换为大写字母,其他字符转换为小写字母 | "hello world".title() |
| str.swapcase() | 将字符串中的大写字母转换为小写字母,小写字母转换为大写字母 | "Hello World".swapcase() |
- upper()方法
该方法将字符串中的所有字母都转换为大写字母。
语法
str.upper()
其中,string是要转换大小写的字符串对象。在调用这个方法时,原始字符串不会被修改,而是返回一个新的字符串对象。
实例1:讲小写字母helloword转换成大写
str = "hello world"
print(str.upper())
输出结果:
HELLO WORLD
- lower()方法
该方法将字符串中的所有字母都转换为小写字母。
语法
str.lower()
其中,string是要转换大小写的字符串对象。在调用这个方法时,原始字符串不会被修改,而是返回一个新的字符串对象。
实例2:将大写字母helloword转换成小写
str = "HELLO WORLD"
print(str.lower())
输出结果为:
hello world
- capitalize()方法
该方法将字符串的第一个字母转换为大写字母,其他字母都转换为小写字母。
语法
str.capitalize()
在调用这��个方法时,原始字符串不会被修改,而是返回一个新的字符串对象。
实例:
str = "hello world"
print(str.capitalize())
输出结果为:
Hello world
- title()方法
该方法将字符串中每个单词的第一个字母都转换为大写字母,其他字母都转换为小写字母。
语法
str.title()
在调用这个方法时,原始字符串不会被修改,而是返回一个新的字符串对象。
实例5:讲Helloworld首字母转为大写
str = "hello world"
print(str.title())
输出结果为:
Hello World
- swapcase()方法
该方法将字符串中的大写字母转换为小写字母,小写字母转换为大写字母。
语法
str.swapcase()
实例5:字符串中的大写字母转换为小写字
string = "Hello World"
print(str.swapcase())
输出结果为:
hELLO wORLD
作业
作业一:将字符串"Hello, World!"转换为大写形式。
作业二:将字符串"Hello, World!"转换为小写形式。
作业三:将字符串"hello, world!"转换为每个单词的首字母大写形式。
作业四:将字符串"Hello, World!"中的大写字母转换为小写字母,将小写字母转换为大写字母。
5种字符串检索方法
本节我们来学习字符串的检索,字符串检索的方法也非常的多,Python提供了五种不同的字符串检索方法。这些方法可以帮助开发者在字符串中查找所需的信息,并处理字符串数据。方法如下:
| 方法 | 作用 | 示例 |
|---|---|---|
find() | 返回字符串中第一次出现指定字符的位置 | "hello world".find("o") 返回值为 4 |
index() | 返回字符串中第一次出现指定字符的位置,如果没有找到则报错 | "hello world".index("o") 返回值为 4 |
count() | 返回指定字符在字符串中出现的次数 | "hello world".count("o") 返回值为 2 |
startswith() | 检查字符串是否以指定的字符开头 | "hello world".startswith("hello") 返回值为 True |
endswith() | 检查字符串是否以指定的字符结尾 | "hello world".endswith("world") 返回值为 True |
- count()方法
字符串计数是在一个字符串中计算给定的子串出现的次数。在Python中,可以使用count()方法进行字符串计数。该方法会返回子串在字符串中出现的次数。如果没有找到,则返回0

语法
str.count(sub[, start[, end]])
sub:要计数的子串。start:计数的起始位置,默认为0。end:计数的结束位置,默认为字符串的长度。
实例1:统计o出现的次数
下面我们来看一下这个count函数它是如何查找的?这里有个字符串叫做love you Python,然后我们要查到什么呢?查找这个字母o在这个字符串中的个数。看一下计数器是怎么计数的?首先碰到第1个o,记为1,然后第2个o,记为2,第3个o,就记为3,那么最终的结果就是输出3。 这里我们需要注意的是,count函数它是区分大小写的。

str = "LoveYouPython"
print(str.count('o'))
输出结果:
3
count()方法返回该字母在字符串中出现的次数3。
- find()方法
字符串查找是最基本的字符串检索方法,其作用是在一个字符串中查找给定的子串。在Python中,可以使用find()方法进行字符串查找。该方法会返回子串所在位置的索引值,如果没有找到,则返回-1。

语法
str.find(sub[, start[, end]])
sub:要查找的子串。start:查找的起始位置,默认为0。end:查找的结束位置,默认为字符串的长度。
实例2:查找o所在的索引位置

下面是一个字符串查找的实例:
str = "LoveYouPython"
print(str.find('o'))
输出结果:
1
- index()函数
当我们需要查找特定字符串在另一个字符串中的位置时,也可以使用字符串的index()方法。该方法可以返回指定子字符串在原始字符串中的位置,如果没有找到,则会引发ValueError异常。

语法:
str.index(sub[, start[, end]])
参数说明:
- sub:需要查找的子字符串。
- start:查找的起始位置,默认为0。
- end:查找的结束位置,默认为字符串长度。
返回值:
- 如果找到,则返回该子字符串在原始字符串中的位置。
- 如果没有找到,则引发ValueError异常。
实例3:查找字符串位置
下面是一个简单的实例来说明index()方法的使用:
str1 = "Hello, World!"
str2 = "World"
# 查找str2在str1中的位置
pos = str1.index(str2)
print("位置是:", pos)
输出:
位置是: 7
在上面的例子中,我们定义了一个字符串str1和一个子字符串str2。我们使用index()方法查找str2在str1中的位置,并将结果存储在变量pos中。最后,我们打印出变量pos的值,即str2在str1中的位置。
- starswith()方法
Python中的starswith()方法是用于判断一个字符串是否以指定的前缀开头,如果是,则返回True,否则返回False。

语法:
str.startswith(prefix[, start[, end]])
其中,str表示需要被检查的字符串,prefix表示需要检查的前缀,start和end表示可选参数,用于指定字符串中需要被检查的起始位置和结束位置。
具体参数解释如下:
- prefix:需要检查的前缀,可以是一个字符串或者是一个元组。
- start:可选参数,表示字符串中需要被检查的起始位置,默认为0。
- end:可选参数,表示字符串中需要被检查的结束位置,默认为字符串的长度。
实例4:startswith方法示例
str1 = "Hello, world!"
print(str1.startswith("Hello")) # True
print(str1.startswith("world", 7)) # True
print(str1.startswith("world", 7, 10)) # False
上述代码中,第一个print语句检查了字符串str1��是否以"Hello"开头,因此返回True。第二个print语句检查了从字符串str1的第7个位置开始,是否以"world"开头,因此返回True。第三个print语句检查了从字符串str1的第7个位置开始,到第10个位置结束的子字符串是否以"world"开头,因此返回False。
- endswith()方法
Python的endswith()方法可以判断字符串是否以指定的后缀结尾,返回值为布尔值True或False。

语法如下:
str.endswith(suffix[, start[, end]])
其中,suffix为必填参数,表示要检查的后缀。start和end为可选参数,表示要检查后缀的字符串范围,即从哪个位置开始检查到哪个位置结束。
参数进行详细说明:
- suffix:需要检查的后缀,可以是一个字符串或者是�一个元组。
- start:可选参数,表示字符串中需要被检查的起始位置,默认为0。
- end:可选参数,表示字符串中需要被检查的结束位置,默认为字符串的长度。
实例5:endswith()方法使用示例
str = "Hello, World!"
print(str.endswith("World!")) # True
print(str.endswith("world!")) # False
print(str.endswith(("World!", "Python"))) # True,因为"World!"是其中一个后缀
实例6:endswith()方法使用示例-添加start参数
str = "Hello, World!"
print(str.endswith("World!", 7)) # True,因为从第7个位置开始的后缀是"World!"
实例7:endswith()方法使用示例-添加start和end参数
str = "Hello, World!"
print(str.endswith("World!", 0, 7)) # False,因为从第0个位置到第7个位置的字符串是"Hello, "
作业
作业一:用户输入的字符串和子串,判断字符串中是否包含该子串,并输出其起始位置。
作业二:用户输入的字符串和子串,用index判断字符串中是否包含该子串,并输出其起始位置。如果字符串中不包含该子串,则输出提示信息。
作业三:用户输入的字符串和子串,统计字符串中该子串的出现次数,并输出结果。
作业四:用户输入的字符串和子串,判断字符串是否以该子串开头,并输出结果。
作业五:用户输入的字符串和子串,判断字符串是否以该子串结尾,并输出结果。
获得作业答案请联系本笔记的配套视频:Python零基础入门动画课【全集】
3种字符串分割方法
本节我们来介绍一下字符串的分割方法,分割方法主要有5种并且整理了表格如下,方便大家查阅
| 方法 | 作用 | 示例 |
|---|---|---|
split() | 将字符串按照指定分隔符分割成多个子字符串,并返回一个列表 | "hello world".split(" ") 返回值为 ["hello", "world"] |
rsplit() | 将字符串按照指定分隔符从右往左分割成多个子字符串,并返回一个列表 | "hello world".rsplit(" ", 1) 返回值为 ["hello", "world"] |
splitlines() | 将字符串按照换行符分割成多个子字符串,并返回一个列表 | "hello\nworld".splitlines() 返回值为 ["hello", "world"] |
partition() | 将字符串按照指定分隔符分割成三部分,并返回一个元组,第一部分是分隔符前面的子串,第二部分是分隔符本身,第三部分是分隔符后面的子串。如果分隔符不存在,则返回原字符串和两个空字符串的元组 | "hello world".partition(" ") 返回值为 ("hello", " ", "world") |
rpartition() | 将字符串按照指定分隔符从右往左分割成三部分,并返回一个元组,第一部分是分隔符前面的子串,第二部分是分隔符本身,第三部分是分隔符后面的子串。如果分隔符不存在,则返回两个空字符串和原字符串的元组 | "hello world".rpartition(" ") 返回值为 ("hello", " ", "world") |
- split()分割方法
split方法可以将一个字符串按照指定的分隔符进行分割,得到一个字符串列表
语法
str.split(sep=None, maxsplit=-1)
其中,str是指要进行分割的字符串,sep是指分隔符,默认为None(即空格)。maxsplit是指最大分割次数,如果指定了这个参数,则最多只能进行maxsplit次分割。如果不指定maxsplit,则默认可以分割所有的部分。
实例
实例1:使用默认分隔符进行分割
如果不指定分隔符,那么split函数将会默认按照空格来进行分割,可以处理一个,也可以处理多个
str1 = "daxiong ketang"
str2 = "daxiong ketang"
result1 = str1.split()
result2 = str2.split()
print(result1)
print(result2)
输出结果:
['daxiong', 'ketang']
['daxiong', 'ketang']
实例2:使用指定分隔符进行分割
我们可以指定一个分隔符来进行分割,例如使用逗号进行分割:
str2 = "大熊,andy,小熊"
result = str2.split(',')
print(result)
输出结果:
['大熊', 'andy', '小熊']
实例3:指定最大分割次数
我们可以指定最大分割次数,例如只分割前两个:
str3 = "daxiong,ketang,andy,teacher"
result = str3.split(',', 2)
print(result)
['daxiong', 'ketang', 'andy,teacher']
- splitlines()方法分割字符串
splitlines()方法是用来将字符串按照行进行分割的函数。它返回一个包含每行内容的列表,每一行都是一个字符串。
语法如下:
str.splitlines([keepends])
其中,参数keepends是可选的,默认为False。如果为True,返回的每行字符串都包含行末的换行符。
实例1:splitlines()方法简单示例
str = 'daxiongketang\nandy\n'
print(str.splitlines()) #默认参数,每行末尾都有一个换行符,splitlines()方法自动将其去除
print(str.splitlines(True)) #带参数keepends=True,返回的每行字符串都包含行末的换行符
输出:
['daxiongketang', 'andy']
['daxiongketang\n', 'andy\n']
实例3:多行字符串进行分割
str = '''daxiong
ketang
andy'''
print(str.splitlines())
输出:
['daxiong', 'ketang', 'andy']
说明:多行字符串中每行末尾都有一个换行符,splitlines()方法自动将其去除。
- split和splitlines的区别
splitlines这个函数它就比split函数多了一个lines,lines,我们知道它是行的意思,那么就是说它用行界定符来进行分割,我们看一下它们之间的区别。split函数默认的情况下是使用空格、\r、\n、\t等等这些空白字符来进行分割的,而是splitlines它是通过行界定符,也就是说\r、\n 或者是\r、\n这些行界定符来进行分割,这就是它们俩的区别。

4.partition()分割方法
Python的partition()方法可以将字符串分割成三部分:分隔符之前的部分、分隔符本身、分隔符之后的部分。该方法返回一个元组,元组中包含三个字符串。
语法:
str.partition(separator)
其中,参数separator是分隔符,可以是任意字符串。
返回值:
该方法返回一个元组,元组中包含三个字符串,分别是分隔符之前的部分、分隔符本身、分隔符之后的部分。
实例1:partition()分割方法示例
str1 = "daxiongketang andy"
print(str1.partition(" "))
输出结果:
('daxiongketang', ' ', 'andy')
作业
作业一:给定一个字符串str1 = "daxiongketang123andy456",包含英文字母和数字,请将其中的数字提取出来,并且以逗号分隔输出。
作业二:有一个多行字符串str1 = "daxiong\ketang\andy",请将其中的每一行都以逗号分隔输出。
作业三:字符串str1 = "Andy python",包含多个单词,请将其中的第一个单词提取出来,并且输出。
作业四:给定一个字符串str1= "daxiong andy",包含多个单词,请将其中的最后一个单词提取出来,并且输出。
作业五:字符串str1 = "daxiongketang andy",包含多个单词,请将其中的每一个单词都逆序输出。
获得作业答案请联系本笔记的配套视频:Python零基础入门动画课【全集】
3种字符串修剪方法
本节我们来介绍一下字符串的修剪方法,这里的修剪指的是,对字符串首尾空格以及特殊的字符进行修剪,字符串有3种修剪方法:strip、lstrip、rstrip方法,如下表所示。
| 方法 | 作用 | 示例 |
|---|---|---|
strip() | 去除字符串开头和结尾的空白字符 | " hello world ".strip() 返回值为 "hello world" |
lstrip() | 去除字符串开头的空白字符 | " hello world ".lstrip() 返回值为 "hello world " |
rstrip() | 去除字符串结尾的空白字符 | " hello world ".rstrip() 返回值为 " hello world" |
- strip()修剪方法
strip()方法用于去除字符串两端的指定字符,默认去除空格。
语法
str.strip([chars]) #chars为可选参数,表示要去除的字符。如果不指定chars,则默认去除空格。
例子1:strip()修剪方法示例
s = ' hello, world! '
print(s.strip()) # 默认去除了字符串两端的空格'
print(s.strip(' !')) # strip()方法去除了字符串两端的空格和感叹号
输出结果:
hello, world!
hello, world
- lstrip()修剪方法
lstrip()方法用于去除字符串左侧的指定字符,默认去除空格。
语法如下:
str.lstrip([chars]) #chars为可选参数,表示要去除的字符。如果不指定chars,则默认去除空格
实例2:lstrip()修剪方法示例
s = ' hello, world! '
print(s.lstrip()) # 默认去除了字符串左侧的空格
输出结果:
hello, world!
- rstrip()修剪方法
rstrip()方法用于去除字符串右侧的指定字符,默认去除空格。
语法如下:
str.rstrip([chars]) #chars为可选参数,表示要去除的字符。如果不指定chars,则默认去除空格
实例3:rstrip()修剪方法
s = ' hello, world! '
print(s.rstrip()) # 去除了字符串右侧的空格
print(s.rstrip('!')) # 去除了字符串右侧的空格和感叹号
输出结果:
hello, world!
hello, world
作业
作业一:字符串str1 = ' andy teacher ',输出字符串的长度、去除两端空格后的长度、去除左侧空格后的长度、去除右侧空格后的长度。
获得作业答案请联系本笔记的配套视频:Python零基础入门动画课【全集】
字符串的格式化
本节我们要介绍的内容是字符串格式化,简单来说,就是我们指定字符串以特定的形式输出。在介绍字符串格式化之前,我们来输出一个例子。
name = 'Andy'
login_time = 10
print('你好'+name+',欢迎登录!这是您登录的第',login_time,'次',sep='')
输出结果:
你好Andy,欢迎登录!这是您登录的第10次
看一下这段简单的输出,print里就有两个变量,一个是name,另一个是login_time,这么一个简单的输出,我们这里又使用了加号,又使用逗号,还使用了一个sep,显然这太啰嗦了,代码的可读性也太差了。
- 什么是字符串的格式化
那么能不能有一种方式来提高代码的可读性呢?这时就需要应用到我们本节要介绍的字符串格式化了,那什么是字符串格式化呢?我们来举一个生活中的例子来更好的理解格式化定义,在医院排队的场景非常常见,首先你去挂号,挂完号你再排队去等待就诊,排队的过程非常漫长,可能一站就是一上午。

然后我们看看大妈们是怎么做的,大妈们用鞋去占位,当排到你的时候,你再去替换你的鞋,这个过程就和我们的字符串格式化非常的相似。
我们看一下这里的print函数,在输出的内容中有几个比较奇怪的字符:你好,%s,后面还有一个%d,最后还有一个%.2f,这些都是什么呢?他们就相当于大妈的拖鞋,它是用来占位的,那么占完位用什么替换呢,给我们后面括号中的内容来替换,用name来替换%s,
login_time,替换%d,cost替换%.2f

- 常用字符串格式化方法
| 方法 | 作用 | 示例 |
|---|---|---|
%格式化 | 将值插入到字符串中的占位符中 | %s %d等是占位符,后面用%进行替换 |
str.format() | 将值插入到字符串中的占位符中 | 是占位符,后面用.format()方法进行替换 |
f-string字符串 | 在字符串前加f,用占位 | 是占位符,可以在花括号内直接输入变量名 |
过时的字符串格式化
用%的形式和string.format函数的形式进行格式化已经是过去式了,在python3.6中正式引入了f-string使用的方式。但是由于很多教程或者是源码依然在使用,所以本节我们先来介绍一下第1种:用%的形式和第2种:string.format
- %字符串格式化
用第1种方%的方式来修改一下这段代码
name = 'andy'
login_time = 10
print('你好+name+'欢迎登录!这是您登录的第”,login_time,'次。',sep='') # 有空格
新增一个话费的变量,用%的方式格式改后
name = 'andy'
login_time = 10
cost = 258.98
print('你好%s,欢迎登录!这是您登录的第%d次。您本次消费%.2f元' % (name,login_time,cost))
输出结果:
你好andy,欢迎登录!这是您登录的第10次。您本次消费258.98元
%格式化的不足
-
阅读代码的时候,我们需要一个一个去匹配前面的%s , %d 和 %.2f。如果字符串再长一些,查找起来就非常不方便。
-
后面的括号里,只支持int , str , 浮点型。而不支持其他的列表或者字典类型。
person = {'name': 'andy', 'login_time': 10,'cost':258.98}
data = (person['name'],person['login_time'],person['cost'],person['name'])
print('你好%s,欢迎登录!这是您登录的第%d次。您本次消费%.2f元。恭喜%s,称为VIP会员。' % data)
- str.format字符串格式化
由于%-formatting的不足,str.format()函数就应运而生了。我们使用str.fromat()函数来修改上面的代码。
name = 'andy'
login_time = 10
cost = 258.98
print('{name}你好,欢迎登录!这是您登录的第{login}次。您本次消费{cost}元。恭喜{name},称为VIP会员。'.format(name=name,login=login_time,cost=cost))
通过上面的形式,可读性就提高了。此外,还可以使用字典类型。例如:
person = {'name': 'andy', 'login_time': 10,'cost':258.98}
print("你好{name},欢迎登录!这是您登录的第{login}次。您本次消费{cost}元。恭喜{name},称为VIP会员。".format(name=person['name'], login=person['login_time'],cost=person['cost']))
f-string格式化(最新)
Python的f-string是一种用于字符串格式化的语法,在Python 3.6及以上版本中被引入。它是一种更简单,更直观,更快速的字符串格式化方式,可以让我们更轻松地在字符串中插入变量或表达式的值。
语法
f-string的语法非常简单,只需要在字符串前面加上字母"f"或"F",然后在字符串中使用花括号来包含变量或表达式,如下所示:
name = 'andy'
print(f'My name is {name}')
输出结果为:
My name is andy
在上面的例子中,我们使用了一个变量name并将其插入到字符串中。需要注意的是,在f-string中,花括号内部可以包含任何有效的Python表达式,包括函数调用、数学运算、比较运算等等。
此外,我们还可以在花括号内部添加一些格式化选项,如下所示:
age = 25
print(f'I am {age} years old')
print(f'I am {age:04d} years old')
print(f'I am {age:+d} years old')
print(f'I am {age:<10d} years old')
输出结果为:
I am 25 years old
I am 0025 years old
I am +25 years old
I am 25 years old
在上面的例子中,我们使用了四个不同的格式化选项来格式化变量age的输出。这些选项可以用来控制变量的输出宽度,精度,对齐方式等等。
下面是一些常用的格式化选项:
| 格式化选项 | 描述 |
|---|---|
| :s | 字符串(默认) |
| :d | 十进制整数 |
| :f | 浮点数 |
| :e | 科学计数法 |
| :g | 自动选择浮点数或科学计数法 |
| :x | 十六进制整数 |
| :o | 八进制整数 |
| :b | 二进制整数 |
| :c | Unicode字符 |
| :r | 字符串的repr形式 |
| :% | 百分号格式 |
实例
实例1:f-string多个变量
# 多个变量
name = 'andy'
age = 18
print(f'我叫{name} ,我{age}岁')
输出结果:
我叫andy ,我18岁
实例2:f-string使用函数
name = 'Andy'
print(f'My name is {name.lower()}')
输出结果:
My name is andy
实例3:f-string使用表达式
a = 10
b = 20
print(f'The sum of {a} and {b} is {a + b}')
输出结果:
30
实例4:f-string控制精度
pi = 3.1415926
print(f'π 保留两位小数位{pi:.2f}')
输出结果:
3.14
实例5:f-string控制对其方式
for i in range(1, 6):
print(f'{i:2d} x {i:2d} = {i*i:2d}')
输出结果:
1x 1= 1
2x 2= 4
3x 3= 9
4x 4=16
5x 5=25
实例6:f-string格式化字典
person = {'name': 'Andy', 'age': 18}
print(f"My name is {person['name']} and I am {person['age']} years old")
输出结果:
My name is Andy and I am 18 years old
作业
作业一:使用f-string输出一个字符串,包含你的姓名和年龄。
name = "Andy"
age = 18
作业二:使用f-string格式化字符串,包含你的姓名和出生日期,出生日期格式为"YYYY年MM月DD日"。
name = "Andy"
birthday = "2000-01-01"
作业三:使用f-string输出一个字符串,包含一个字典中的所有键和值,每个键值对占一行。
person = {"name": "Andy", "age": 18, "gender": "男"}
作业四:使用f-string格式化字符串,number = 1234,并且这个数字的输出宽度为8,左对齐,不足8位时用0填充。
获得作业答案请联系本笔记的配套视频:Python零基础入门动画课【全集】
字符串常用方法
本节我们来介绍一下字符串的常见操作,字符串是Python中最常用的数据类型,所以Python提供了非常多的操作字符串的方法,而这些方法是Python自带的,我们也称之为字符串内置方法,首先呢,你需要对这个字符串方法有一个大概印象,知道字符串有一些常用的方法,这样在以后编程的过程中你遇到相似的问题,第1个你就会想到,字符串大概有一个这样的方法,然后你再去查找下面这个文档。最后再看一下具体的使用方法,这就足够了。下面按照使用程度的高低给大家做了一个字符串常用方法的表格,并且每个方法带超链接,点击方法名字,都有对各个方法的详细介绍。
| 方法 | 描述 | 使用程度 |
|---|---|---|
| count() | 返回字符串中子字符串出现的次数 | 非常常用 |
| find() | 查找字符串中是否存在指定的子字符串,并返回其第一次出现的位置 | 非常常用 |
| format() | 将字符串格式化为指定的样式 | 非常常用 |
| join() | 将字符串序列连接为一个字符串 | 非常常用 |
| replace() | 将字符串中指定的子字符串替换为另一个字符串 | 非常常用 |
| split() | 分割字符串 | 非常常用 |
| endswith() | 检查字符串是否以指定的后缀结束 | 一般 |
| isalnum() | 检查字符串是否只包含字母和数字 | 一般 |
| isalpha() | 检查字符串是否只包含字母 | 一般 |
| isdecimal() | 检查字符串是否只包含十进制数字 | 一般 |
| isdigit() | 检查字符串是否只包含数字 | 一般 |
| islower() | 检查字符串中的所有字母是否都是小写 | 一般 |
| isnumeric() | 检查字符串是否只包含数字字符 | 一般 |
| isspace() | 检查字符串是否只包含空格 | 一般 |
| istitle() | 检查字符串是否符合标题格式 | 一般 |
| isupper() | 检查字符串中的所有字母是否都是大写 | 一般 |
| ljust() | 返回一个左对齐的字符串 | 一般 |
| lower() | 将字符串中的所有字母转换为小写 | 一般 |
| lstrip() | 返回去除左侧空格的字符串 | 一般 |
| startswith() | 检查字符串是否以指定的前缀开始 | 一般 |
| strip() | 返回去除左右两侧空格的字符串 | 一般 |
| swapcase() | 将字符串中的大小写字母进行转换 | 一般 |
| title() | 将字符串转换为标题格式 | 一般 |
| capitalize() | 将字符串的第一个字符转换为大写字母 | 一般 |
| center() | 返回一个指定宽度的居中字符串 | 一般 |
| expandtabs() | 将字符串中的制表符转换为空格 | 较少 |
| casefold() | 将字符串转换为小写,并删除所有大小写字母的差异 | 较少 |
| encode() | 将字符串编码为指定的编码格式 | 较少 |
| format_map() | 使用映射来格式化字符串 | 较少 |
| isidentifier() | 检查字符串是否是一个合法的标识符 | 较少 |
| isprintable() | 检查字符串是否可打印 | 较少 |
| maketrans() | 创建一个字符映射转换表 | 较少 |
| partition() | 在指定的分隔符处将字符串分割成三个部分 | 较少 |
| rfind() | 查找字符串中是否存在指定的子字符串,并返回其最后一次出现的位置 | 一般 |
| rindex() | 查找字符串中是否存在指定的子字符串,并返回其最后一次出现的位置 | 一般 |
| rjust() | 返回一个右对齐的字符串 | 一般 |
| rpartition() | 在指定的分隔符处将字符串分割成三个部分,从右侧开始查找 | 较少 |
| rsplit() | 从右侧开始分割字符串 | 较少 |
| rstrip() | 返回去除右侧空格的字符串 | 一般 |
| splitlines() | 分割字符串为行 | 较少 |
| translate() | 使用指定的映射表转换字符串 | 较少 |
| upper() | 将字符串中的所�有字母转换为大写 | 一般 |
| zfill() | 在字符串左侧填充指定的零 | 较少 |